Conditional Probability
Definition
The conditional probability of given is given by:
It is important to note that the above is an abuse of notation, since is not a set in the sigma-algebra to which the probability function can be applied. Hence should not be viewed as applying the function , but just special notation for the formally defined statement the probability of given , or as a special function of two sets in the sigma algebra.
Intuition
This is a definition, and hence cannot be incorrect, however it is useful to justify why this definition is consistent with the idea of the probability of occurring assuming that has occurred.
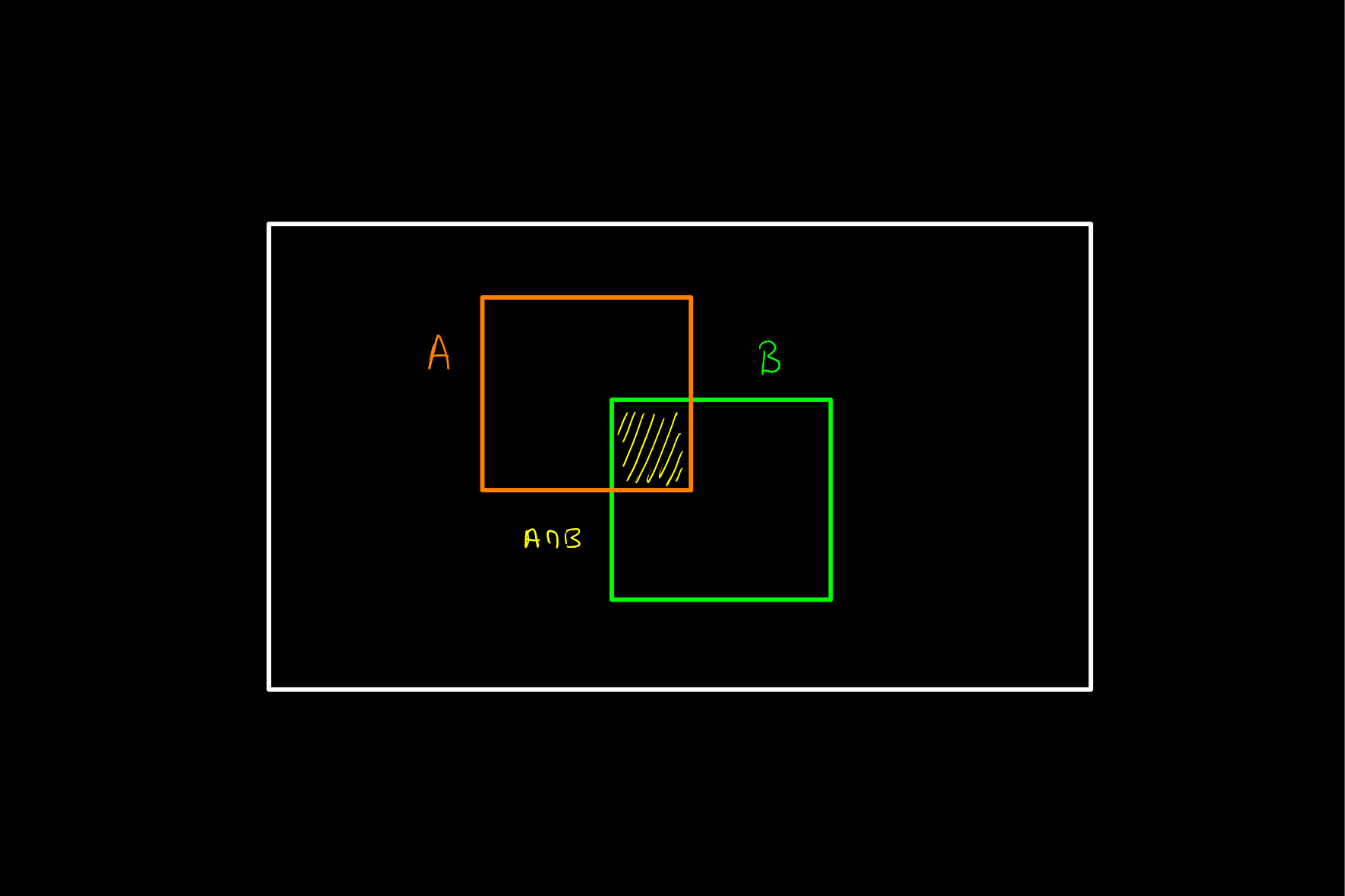
Consider for example a sample space with potentially overlapping events and , where we wish to calculate the probability of given .
Since we know has occurred, we can use this information to restrict our sample space to alone, this giving a better calculation for the probability of . The set of elements in the sigma algebra which are a subset of
is a -algebra on using the same measure.
This -algebra contains only the events in which has occurred (those that overlap with ).
Then, we could measure elements within this new sigma algebra with the same measure as the main probability space, however in order to make itself a probability space we divide by the measure of the space . That is, we construct a new measure by:
from the original measure on .
This is a measure since we only multiply by a scaling factor.
This leaves one problem to resolve, being that might not actually be in the sigma algebra , as it may not be a subset of :
This is simple to resolve, by instead taking the measure of , since we are assuming has occurred anyway, and is measurable in the new measurable space .
This leaves our new probability formula:
Hence, intuitively, using the above diagram where probabilities are represented by areas, the probability of given is equal to the proportion of the area taken up by which is also occupied by .
An important note to make is that often one may view and as events regarding different things, and hence consider them in different sample spaces. For example, one may consider the probability that someone is sick, and the probability that they have been coughing as being in two separate probability spaces. This is easily resolvable by considering the space to be the set of all states of both sickness and coughing. That is, in a simple case, if we previously had the sample spaces:
both with the power set -algebra, then we can construct a new sample space using the Cartesian product, which happens to be the product measurable space if the events are independent (and otherwise is not).